Arsitektur Kubernetes
Pengenalan arsitektur kubernetes (K8s)
Terdapat beberapa bagian yang menjadi penyusun K8s agar dapat berjalan yaitu:

Pada bagian high level terdapat minimal satu node sebagai control plane dan satu node sebagai worker node.
Master node diharuskan untuk online agar tidak menjadi petaka jika sistem sedang running, karena master node merupakan bagian yang penting untuk digunakan sebagai control-plane dalam memanage kluster Kubernetes. Agar master node memiliki sifat High Availability (HA) maka diperlukan untuk mengaktifkan replika pada master node dan hanya mendedikasikan salah satu master node saja untuk proses kontrol sehingga bagian control-plane tetap sinkron dengan replica master node yang lain.
Jenis konfigurasi di atas menambahkan ketahanan ke control-plane cluster, jika master node mengalami kegagalan. Untuk berkomunikasi dengan kluster Kubernetes, pengguna mengirim permintaan ke control-plane melalui alat Antarmuka Baris Perintah (CLI), Dasbor Antarmuka Pengguna Web (UI Web), atau Antarmuka Pemrograman Aplikasi (API).
Penyimpanan status/state dari kluster dilakuan dengan menggunakan etcd. etcd merupakan penyimpanan terdistribusi dengan menggunakan prinsip key-value, piranti ini dapat dikonfigurasi pada master node (stacked topology) atau dedicated host (external topology) untuk membantu mengurangi kemungkinan hilangnya penyimpanan data dengan memisahkannya dari agen control-plane lainnya. Pada stacked topology, replika mengenai data dilakukan secara resilent
Pada stacked topology, replika master node HA memastikan ketahanan penyimpanan data etcd juga. Namun, tidak demikian halnya dengan external topology etcd, di mana host etcd harus direplikasi secara terpisah untuk HA, sehingga konfigurasinya akan membutuhkan perangkat keras tambahan.
Pada master node akan menjalankan beberapa komponen control-plane agar K8s bekerja secara baik, yaitu:
Selain itu terdapat tambahan seperti
Semua beban kerja administrative dikoordinasikan oleh `kube-apiserver` yang telah berjalan pada master node. Server API akan menerima request dari user, lalu melakukan validasi terhadap input yang diterima, baru memprosesnya. Selama proses tersebut maka kluster akan membaca data status/state yang telah tersimpan di etcd, lalu setelah itu jika terjadi perubahan akan disimpan kembali berdasarkan key-value. Server API adalah satu-satunya komponen master plane yang dapat terhubung dengan penyimpanan data di etcd, baik untuk membaca dan menyimpan informasi status cluster Kubernetes, bertindak sebagai antarmuka tengah (middleware) untuk agen control-plane lainnya yang menanyakan status cluster.
Scheduler (kube-scheduler) berperan untuk menetapkan objek beban baru, seperti pods, ke node. Proses penjadwalan dibuat berdasarkan state dari kluster Kubernetes yang digunakan dan requirement dari objek baru. Scheduler akan mendapatkan nilai state dari etcd melalui API Server beserta resource yang digunakan pada tiap nodes. Selain itu, scheduler mendapatkan requirement (sebagian konfigurasi objek) objek baru juga dari API Server. Requirement dapat memuat batasan yang ditetapkan untuk membuat scheduler melakukan pekerjaan ini pada kriteria tertentu, format untuk membuat requirement seperti pasangan key:value, misalnya disk==ssd. Scheduler juga memperhitungkan requirement seperti Quality of Service (QoS),data locality, affinity, anti-affinity, taints, toleration, cluster topology, dll. Setelah semua data kluster tersedia, algoritma scheduing akan memfilter node dengan predikat untuk diisolasi sebagai kandidat node yang mungkin memenuhi semua persyaratan untuk menampung beban kerja baru. Hasil dari proses keputusan dikomunikasikan kembali ke API Server, yang kemudian mendelegasikan penyebaran beban kerja dengan agen bidang kontrol lainnya.
Scheduler dapat dikonfigurasi melalui kebijakan scheduling, plugins, dan profil. Tambahan penjadwalan yang disesuikan(custom) juga tersedia untuk dikonfiguras, maka data konfigurasi objek diperlukan dengan menyertakan nama scheduler costom yang diharapkan membuat keputusan penjadwalan untuk objek tertentu; jika tidak ada data yang disertakan, scheduler default dipilih sebagai gantinya.
Penjadwal sangat penting dan kompleks dalam cluster Kubernetes multi-node.
Controller managers adalah bagian komponen master node yang memiliki fungsi untuk mengatur state kluster Kubernetes. Controller akan berjalan secara terus menerus (watch-loop) untuk membandingkan state yang diinginkan pengguna dengan state yang sekarang (data state didapat dari etcd melalui API Server)
Kube-controller-manager bertanggung jawab untuk menjalankan pengontrol ketika node menjadi tidak tersedia, memastikan jumlah pod seperti yang diharapkan, membuat endpoint, service account, dan token API.
Cloud-controller-manager berfungsi untuk berinteraksi dengan infrastruktur penyedia cloud saat node menjadi tidak tersedia, mengelola volume penyimpanan saat disediakan oleh layanan cloud, dan mengelola load balancing dan rute.
Data store yang digunakan dalam kubenetes adalah etcd, penyimpanan berbasis key-value terdistribusi dan konsisten dalam mempertahankan state dari kluster kubernetes. Ketika ada data baru, maka data tersebut akan di append ke key yang sudah ada, sehingga data lama tidak hilang. Data lama yang tersimpan secara berkala dicompress agar membuat penyimpanan data yang besar menjadi lebih kecil, sehingga dapat menghemat storage. Untuk berkomunikasi dengan etcd, komponen control-plane hanya dapat dilakukan melalui pemanggilan API Server.
Pada etcd, terdapat aplikasi cli yaitu etcdctl yang memiliki fungsi untuk memberikan backup, snapshot, dan restore pada instance suatu kluster Kubernetes. Pada tahap production sangat disarankan untuk menggunakan mereplikasi data di etcd dengan mode HA (high available) agar bisa menjaga ketahanan data dari kluster.
Beberapa tools bootsrapping Kubernetes, kubeadm secara default menggunakan etcd stacked ha topology untuk menyimpan data dan berbagi resource antar komponen control-plane yang lainnya pada node yang sama.

Mode etcd eksternal dapat dikonfigurasi dengan tujuan untuk mengurangi kemungkinan jika terjadi kegagalan pada etcd. Hal ini terjadi karena etcd dedikasikan dengan host yang terpisah dimana data itu akan tersimpan.

Proses switch untuk mengatasi kegagalan pada etcd dengan mode HA di stacked dan eksternal menggunakan algoritme Raft Consensus dimana memungkinan kumpulan mesin bekerja di grup secara koheran yang dapat bertahan dari beberapa anggota mesin lainnya. Pada waktu tertentu, salah satu node dalam grup akan menjadi master, dan sisanya akan menjadi pengikut, etcd akan menangani pemilihan master dan dapat mentolerir kegagalan node, termasuk kegagalan master node. Setiap node dapat diperlakukan sebagai master.
Worker node menyediakan environment untuk menjalankan aplikasi melalui container microservices yang dibundle pada pod dan dapat dikontrol melalui control-plane pada master node. Pod dijadwalkan pada worker-node, di mana tiap pod akan menemukan resource komputasi, memori dan penyimpanan yang diperlukan untuk dijalankan, dan jaringan untuk berkomunikasi satu sama lain dan juga dunia luar. Pod merupakan unit terkecil pada di Kubernetes.
Selain itu, dalam multi-worker Kubernetes cluster, lalu lintas jaringan antara client dan aplikasi yang tercontainerized akan dideploy oleh Pod dan ditangani langsung oleh worker-node, juga tidak dirutekan melalui node master.
Container runtime berperan untuk mengelola siklus dari container. Kubernetes memerlukan container runtime pada node, dimana tempat Pod dan containernya dijadwalkan. Kubernetes mendukung banyak container runtime :
Agar dapat berkomunikasi dengan control-plane master node, tiap worker-node terdapat agent bernama kubelet. Kubelet menerima definisi Pod dan berinteraksi dengan container runtime pada node untuk menjalankan container pada Pod. Lalu, juga memonitor kesehatan dan resource Pod yang menjalankan container.
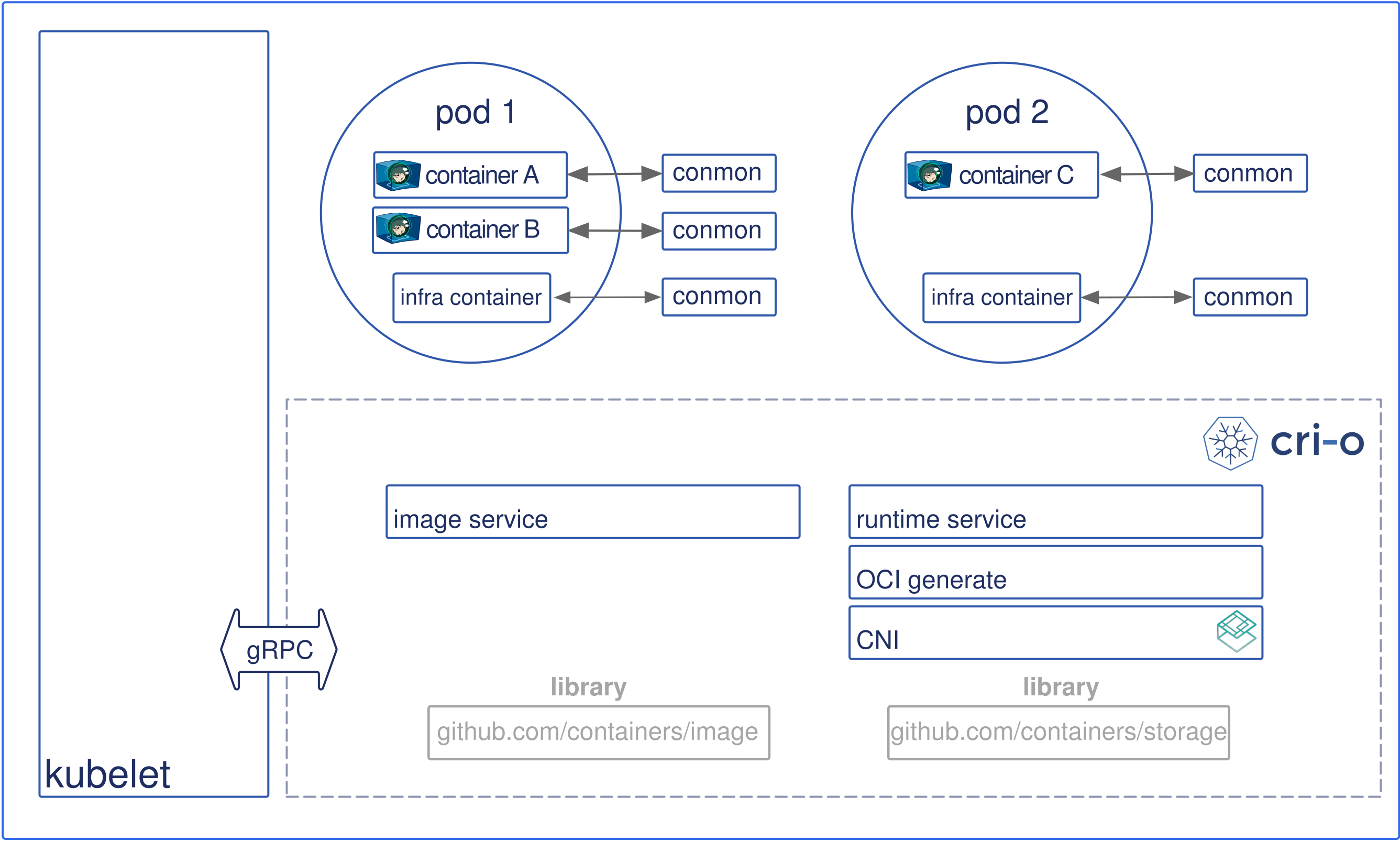
kubelet terhubung dengan container runtime dengan sebuah plugin interface yaitu Container Runtime Interface (CRI).CRI terdiri dari protocol buffer, gRP API, library dan tambahan spesifikasi dan beberapa tools yang sedang dikembangkan. Untuk dapat terhubung ke container runtime, kubelet menggunakan shim yang menyediakan laisan abstraksi antara kubelet dan container runtime

Seperti yang terlihat pada gambar diatas, kubelet berperan sebagai grpc client yang terhubung dengan CRI shim (grpc server) untuk melakukan operasi container dan image. Terdapat 2 service yaitu ImageService dan RuntimeService. ImageService bertangung jawab terhadap operasi yang berkaitan dengan image. RuntimeService bertanggung jawab atas semua Poda dan operasi container.
Kubernetes support beberapa container runtime, pada bagian ini akan melihat implementasi Shim pada masing-masing container runtime intrface.
Container dibuat dengan Docker yang sudah terinstall pada worker-node. Secara internal, docker menggunakan conteinerd untuk membuat dan me-manage container.

Melalui cri-containerd, secara langsung dapat menggunakan containerd untuk membuat dan me-manage container

CRI-O bisa digunakan untuk semua yang kompatibel dengan Open Container Initiative (OCI) runtime di Kubenertes. CRI-O saat ini mendukung runC dan Clear Containersebagai runtime, namun pada prinsipnya jika sesuai dengan OCI maka dapat dijalankan.
Implementasi CRI dengan frakti memungkinan pada level virtualisasi hardware yang bertujuan untuk keamanan dan isolasi yang lebih baik daripada di tingkat Linux OS yang berdasar pada cgroup dan namespace. Frakti CRI shim juga memungkinkan untuk berinteraksi antara kubelet dengan Kata Container:

Kube-proxy adalah agen jaringan yang berjalan pada setiap node dengan tanggung jawab sebagai maintnance semua aturan jaringan pada node dan dynamic update. Hal ini mengabstraksi detail jaringan pada Pod dan meneruskan permintaan koneksi tersebut ke Pod.
Kube-proxy berperan untuk meneruskan koneksi TCP, UDP, dan SCTP dengan cara round-robin di seluruh kumpulan backend Pod. Untuk mengatur rulenya, user dapat mengontrol melalui Service API
Addons adalah fitur kluster dan secara fungsional belum tersedia di Kubernetes sebelum diimplementasikan melalui third party pods dan services.
Reference :